
Aindo named as a Sample Vendor in the 2026 Gartner® Emerging Tech Impact Radar for Conversational AI
How synthetic data is becoming the foundation for clinical evidence generation and specialized AI development
An overview of Generative AI
Artificial Intelligence (AI) has recently received a lot of media attention. Companies are becoming aware that AI is vital in sustaining a competitive position. For example, most healthcare providers aim to use AI for algorithmic medicine. This application directly impacts patients’ quality of life.
Unfortunately, AI techniques often rely on the processing of large quantities of data. Especially in sectors like healthcare and finance, such data is confidential. With increased AI familiarity came a broad understanding of the involved privacy risks. Luckily, a revolutionary privacy technology has emerged: synthetic data generation.
Records in a synthetic dataset are entirely artificial, and therefore do not contain sensitive information of any real individual. Through generative AI, synthetic data can be constructed that preserves all the intricate patterns of a real dataset. Thus, SD makes analysis and AI development possible without posing privacy risks. Like portraits of non-existing people generated by AI tools, synthetic datasets are highly realistic, but do not pertain to real individuals.
SD technology is successfully applied in industries such as finance, healthcare and the public sector. In fact, Gartner predicts that by 2024, 60% of the data used for the development of AI and analytics projects will be synthetically generated 1. However, the field’s highly innovative and technical nature raises many questions.
In this blog, we answer these questions by providing an introduction to the technology behind synthetic data. To do so, we first provide an intuitive outline of the involved methods. We then discuss deep generative models in more detail. Finally, we will look at the complexities that arise when applying synthetic data technology to advanced data types and formats.
Highly realistic synthetic data are constructed through generative artificial intelligence (AI) techniques. These techniques are all the rage these days: chatGPT, stable diffusion and many other famed systems are all applications of generative AI. All generative AI methods follow the same basic steps, namely, the method:
Thus, generative AI methods have to infer the intricate multivariate distribution of the dataset. This also means that the nuanced interactions between variables have to be captured. If this inference is successful, then the new samples will exhibit the same behavior as real data points. This means that the obtained synthetic data can be used in place of the real ones for all sorts of applications, such as software development, advanced analysis and development of AI models.
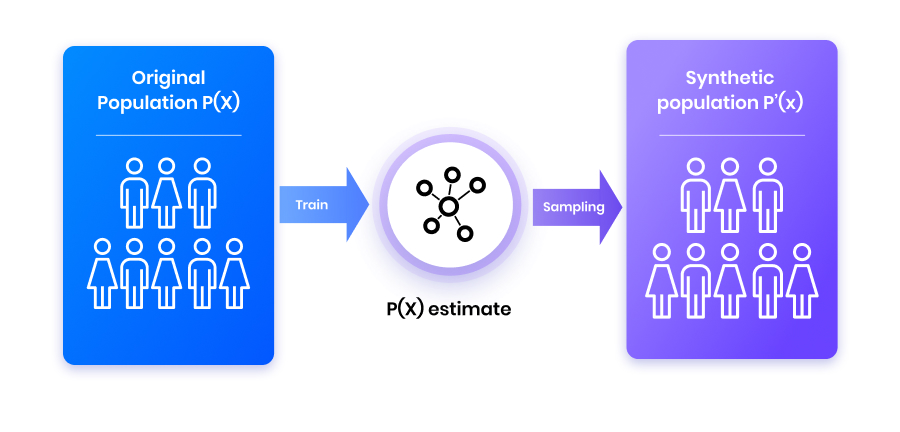 Generative models capture data properties in a probability distribution and subsequently take samples from it.
Generative models capture data properties in a probability distribution and subsequently take samples from it.
The most cutting edge generative models are deep generative models (DGMs). DGMs use artificial neural networks to infer and sample from distributions. The most popular synthetic data technologies are all DGMs: Generative Adversarial Networks (GANs) 2, denoising diffusion models 3, and Variational Autoencoders (VAEs) 4.
DGMs were originally conceived for the generation of synthetic images. Mathematically, each pixel in an image can be described as a collection of numbers. For example, in a black and white image, the gray shade of each pixel is represented as a number between 0 and 255 (the grayscale), with larger values corresponding to lighter shades of gray.
For generative AI methods, such representations of images are a double-edged sword. On the one hand, they lead to a high dimensionality, as each pixel is represented separately. This means that a lot of information has to be processed during training, which is therefore very time-consuming. On the other hand, all the pixels are represented using the same, easy to interpret numeric scale: a red value of 100 means the same gray shade for a pixel in the middle of the image as it does for an image in a corner.
Unlike images, organizational data (medical records, customer details, financial transactions, etc.) are typically collected in tables with many highly different attributes. For example, a healthcare database may contain a patient’s blood type and her age. The former is a categorical attribute: its value is always in one of four categories (A, B, AB or O). The latter is a numeric attribute (or simply put: a number). Thus, unlike color values in images, each attribute in an organizational database has a completely different interpretation.
As DGMs were developed for image synthesis, they presume that data is represented in a homogenous way, like grayscale values in images. They can therefore not readily be applied to organizational data. To use DGMs in this context, we have to first transform the data to a more homogenous representation. The transformed data is referred to as an embedding. DGMs can be trained on embeddings and subsequently sampled. Like the embeddings, the sampled synthetic data are then also homogenous. Thus, we have to undo the data transformation, obtaining synthetic data with the original attributes.
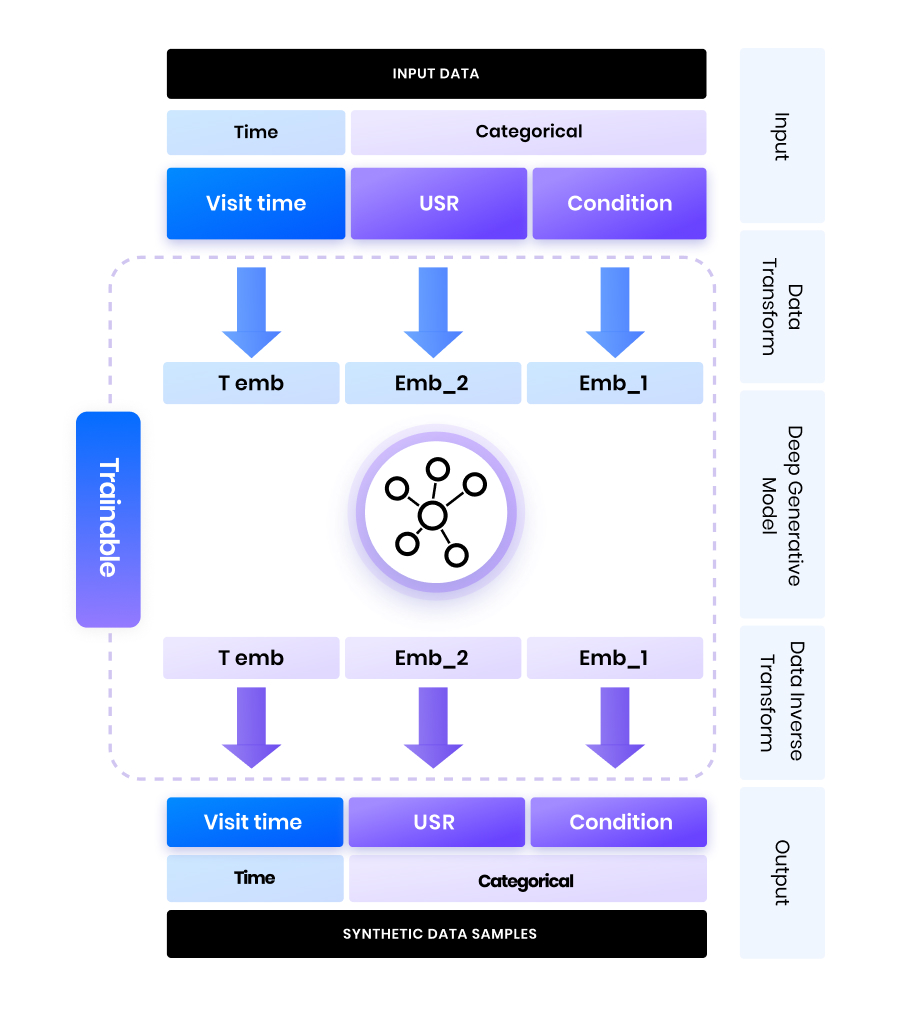 Generative models for tabular synthetic data have to include strategies to ingest and generate diverse data types.
Generative models for tabular synthetic data have to include strategies to ingest and generate diverse data types.
At Aindo, we have developed patented 5 novel techniques to transform all data types in organizational data to homogenous embeddings 6. Combined with theoretical innovations for DGMs, this allows us to generate realistic synthetic data for even the most advanced (combinations of) data types (numeric, categorical, date-time, time series, geolocation data, and more).
In many practical cases, information is stored in relational databases. Such databases consist of multiple interconnected tables. Each table contains information about a different aspect of the same topic. For example, consider a public healthcare dataset in which patient visits to clinics are documented. This dataset can consist of multiple tables:
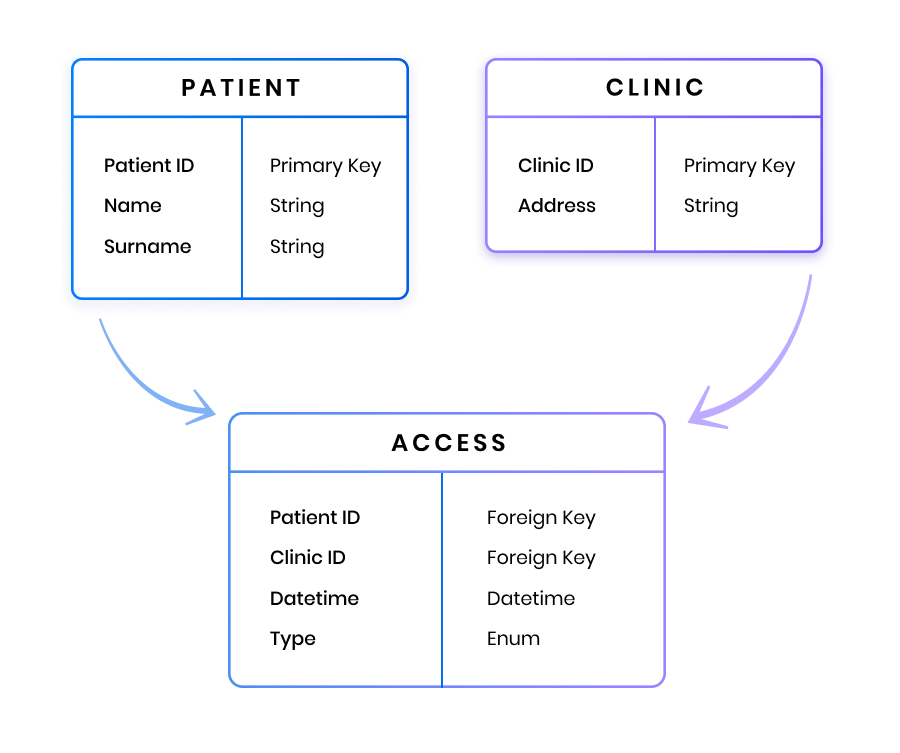 In this relational database example, the visits of patients to clinics are recorded in different tables, linked by “foreign keys”, that is: identification numbers for specific patients and clinics.
In this relational database example, the visits of patients to clinics are recorded in different tables, linked by “foreign keys”, that is: identification numbers for specific patients and clinics.
Generating synthetic relational data is challenging, as the DGM should not only infer patterns in specific tables. Rather, it should also recognize and replicate the relations between the tables.
This challenge is sometimes addressed by attempts to compress (or flatten) the information into a single table. For example, for each clinic visit in the visit table, we could take all the patient information from its table and add it to the visits table. This approach unfortunately leads to poor results: the rows in the flattened table lack properties presumed by DGMs (for example, statistical independence).
At Aindo, we have developed a revolutionary methodology to create realistic synthetic relational data. This methodology combines the theory of DGMs with graph neural networks. The results dramatically outperform the table flattening solution and were presented at the NeurIPS 2022 Synthetic Data workshop, the most prestigious conference in AI. In a future blog, we dive deeper into this revolutionary approach!
In this blog, we demystified synthetic data, by giving an overview of the involved technology. In particular, we discussed that synthetic data is typically generated by inferring patterns from real data, capturing them in the form of a probability model, and taking random samples from this model. We then introduced the most common framework for doing so: deep generative models. We saw that this framework was originally conceived for image generation. This means that organizational data requires a sophisticated transformation for the framework to be applicable. Finally, we discussed the difficulty of accurately generating synthetic relational data, in which information is contained in several interconnected tables.
White, Andrew. “By 2024, 60% of the data used for the development of AI and analytics projects will be synthetically generated.” Gartner, 2021. ↩
Courville, Aaron, and Yoshua Bengio. “Generative adversarial nets.” Advances in Neural (2014). ↩
Ho, Jonathan, Ajay Jain, and Pieter Abbeel. “Denoising diffusion probabilistic models.” Advances in Neural Information Processing Systems 33 (2020): 6840-6851. ↩
Kingma, Diederik P., and Max Welling. “Auto-encoding variational bayes.” arXiv preprint arXiv:1312.6114 (2013). ↩
Italian Patent No. 102021000008552 ↩
Panfilo, Daniele. Generating Privacy-Compliant, Utility-Preserving Synthetic Tabular and Relational Datasets Through Deep Learning. University of Trieste, (2022). ↩
How synthetic data is becoming the foundation for clinical evidence generation and specialized AI development

Synthetic data is not just a privacy tool. It is the foundation of a new healthcare data infrastructure—one that makes data usable at scale.

Using synthetic data to unlock virtual patients
What we look for
Beyond your technical background, we look for:
What we offer
💡 Growth & Impact: join a fast-growing company where you’ll lead strategic projects, shape solutions and see the tangible impact of your work
🌴 Flexibility & Wellbeing: hybrid or fully remote work, ticket restaurant and health insurance
🤝 Collaborative Culture: work in autonomous teams with highly talented colleagues, in a supportive, innovative and ethical environment
How to apply
To apply, please send your CV and a motivation letter to [email protected], with the subject “Spontaneous Application - [Your Area of Expertise]”.
Aindo is an Equal Opportunity-Affirmative Action Employer – Minority / Female / Disability / Veteran / Gender Identity / Sexual Orientation / Age.